Qichwabase
 Image credit: Elwin Huaman
Image credit: Elwin HuamanThe availability of interoperable linguistics resources is nowadays more urgent in order to save and help under-resourced languages and their communities. Despite these efforts, not all languages are represented or made accessible in a structured format, and their indigenous communities and their resources have received less attention.
To overcome these limitations, we propose a general approach of building knowledge bases for under-resourced languages based on the Wikimedia infrastructure. Our approach has been validated with the Puno Quechua language, and it is described in the following Qichwabase workflow:
Qichwabase Workflow
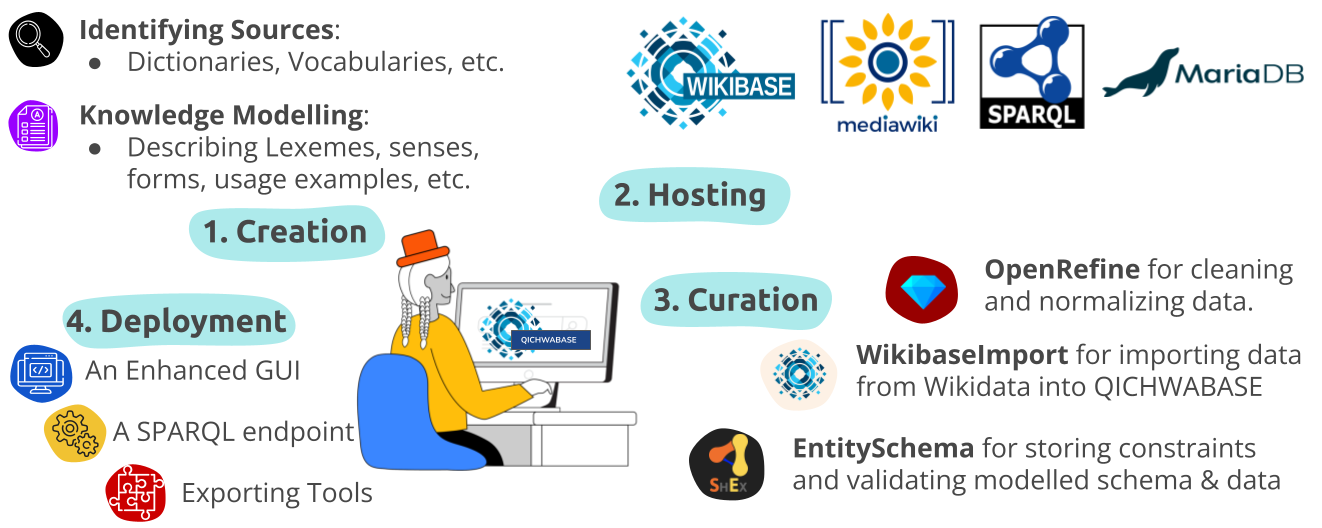
- Identifying sources: In this step, various data and knowledge sources are retrieved and collected. For instance, dictionaries, vocabularies, multiword expressions, books, etc.
- Data modelling: It describes the structure under which the identified resources will be modelled. For example, for describing lexicographical data, it is a good approach to visit all documentation on Wikidata Lexemes.
- Hosting infrastructure: In this step, a host for the knowledge base is selected, e.g. Wikibase is the infrastructure that drives Wikidata.
- Knowledge ingestion: It describes the ways to validate and import data into the knowledge base. For instance, it can be manual or semi-automatic.
- Reconciliation (OpenRefine): It is important to avoid duplicates into the knowledge base. The reconciliation task prevents from importing duplicate entities, lexemes, etc.
- WikibaseIntegrator: It allows the ingestion of large amounts of data into the knowledge base.
- EntitySchema: It allows the definition of constraints for modelled data in the knowledge base. Furthermore, it is also possible to create forms in order to allow users to enter data that must conform to the constraints.
- Deployment infrastructure: It should allow the language community to contribute, improve, and validate the knowledge in the knowledge base. Additionally, it must provide ways for users, researchers, and language learners to retrieve the knowledge.
Objectives
A series online and offline workshops were organized in Peru to familiarize Quechua speakers with the approach and on how they can help and contribute in the curation of the knowledge on Qichwabase. The following objectives have been addressed:
- Keep the linguistic diversity of Puno quechua orality with Lingualibre, which allows the recording of voice messages for words, phrases, and more.
- Document current events via Wikimedia Commons, which allows users to contribute with media resources, such as images and recordings.
- Decentralize demographic contributions with Wikibase, which allows communities to design, create, curate and deploy a mature decentralized knowledge base.
- Engage educators, students, researchers, and developers to work together for a more inclusive internet for the next generations.
How does it relate to the collaboration of the open?
We want to show the efforts we are doing regarding the quechua language and its communities. This could help other communities to address similar issues.
- Collaboration. We developed methods, tools, and guidelines that can be reused across Quechua language communities, and adapted to any community or language.
- Open. We aimed that minority communities from South America can work closely together in order to leverage and improve the development of common approaches to save knowledge and bring inclusiveness and diversity to the movement.
